Editor’s Note: Welcome to Chapter 1 of Understanding and Preventing Entra ID Agent Identity Attacks: A Comprehensive Guide. This multi-part technical walkthrough helps you understand Microsoft’s approach to agent identities and how you can protect them from threat actors. To review all the chapters and practice lessons, start here.
Any digital operation that crosses system boundaries stops being just “code.” The moment it needs to interact with another system in a meaningful way—call an API, read protected data, or modify state—it has to take a structural form that other systems can recognize, evaluate, and trust. That form is a digital identity.
In practice, this means a distinguishable directory-backed object—a security principal that can be granted permissions, assigned roles, evaluated by access control mechanisms, and recorded in audit logs. Code can cross boundaries freely but ideally it can’t access anything of value without doing so through an identity.
For this reason, in distributed architectures, identity is not just a representation or an abstraction layer but the unit of control. Systems exchange it and base access decisions on it when it matters: as it moves across boundaries, persists beyond the runtime that created it, and enables digital operations to exist and run outside their original electronic context.
At a high level, digital identities in Microsoft Entra ID (and in most modern digital ecosystems) fall into two categories: human identities and machine—or non-human—identities. What’s the difference?
Human identities represent people. Employees, frontline workers, customers, consultants, vendors, and partners typically authenticate as user objects. They sign in interactively, are evaluated by user-focused Conditional Access policies, and usually operate under a single primary identity.
Non-human identities (NHIs) represent, well, everything else operating inside the system that is not a person. These identities can be roughly divided into two main categories:
- Device identities, which represent hardware: physical devices such as desktop computers, mobile devices, IoT/OT sensors, and managed endpoints
- “Workload” identities, which represent software workloads: applications, pipelines, scripts, service accounts, bots, agents, and other types of automation accounts
Regardless of type, most identities move through the same quiet cycle in the digital landscape. They authenticate (prove to the approached system who they claim to be); are authorized (the system determines what they are allowed to do in its programmable context); and are accounted for (their actions are logged and traceable).
This is the classic Authentication, Authorization, and Accounting (AAA) model. It applies to everything, humans and non-humans alike. Every identity enters a system, requests access, performs work, and leaves a footprint behind.
This pattern might feel familiar because not long before we designed digital systems, we structured the physical world around identity, authority, responsibility, and most important, trust. As developers, we simply, and maybe unconsciously, emulate the same archetypes in software.
Perhaps for that reason, digital identity has become the control plane of the resources around it. Consequently, identity is also the primary attack surface for manipulation, impersonation, and misuse.
That’s why, when a digital identity is compromised, the attacker does not break or change anything in the system. Instead, they operate in it under a valid principal, moving across software-defined boundaries with legitimate assertions and tokens. Non-human identities are no exception to this dynamic, and in most environments, they represent a broader and far less visible exposure than human users.
In this guide, we examine a new non-human identity type that Microsoft recently introduced in Entra ID: agent identities.
Built to support the rapid and somewhat relentless growth of AI agents and the broader class of automation workloads, this model extends the longstanding Service Principal, Application, and User architectures into a new operational domain.
To appreciate why this matters, we first need to step back and understand that most identities operating in modern cloud environments are not people at all.
Why non-human identities actually matter more than users
There is a digital-old assumption in security that user accounts are the crown jewels that must be protected above all else. That instinct made sense when humans were the primary actors in digital systems. But once identity becomes the control plane and more software integrations propagate throughout the internet’s ecosystem, scale becomes what defines risk.
In Microsoft’s 2024 State of Multicloud Security Report, that scale becomes very visible. The report states:
“As more and more companies move their workloads to the cloud, we’re seeing a rapid growth in the number of workload identities being created. Today, there is one human identity for every 10 workload identities. This problem is even more acute among small- and medium-sized businesses, which have one human identity for every 50 workload identities.”
Across customer environments analyzed in 2023, Entra Permissions Management identified 209 million cloud identities. More than 83% of them were non-human.
And that was 2023.
Since then, with the acceleration of cloud-native architectures, large-scale integrations, and the rapid adoption of AI-driven automations, the number of non-human identities has increased dramatically.1
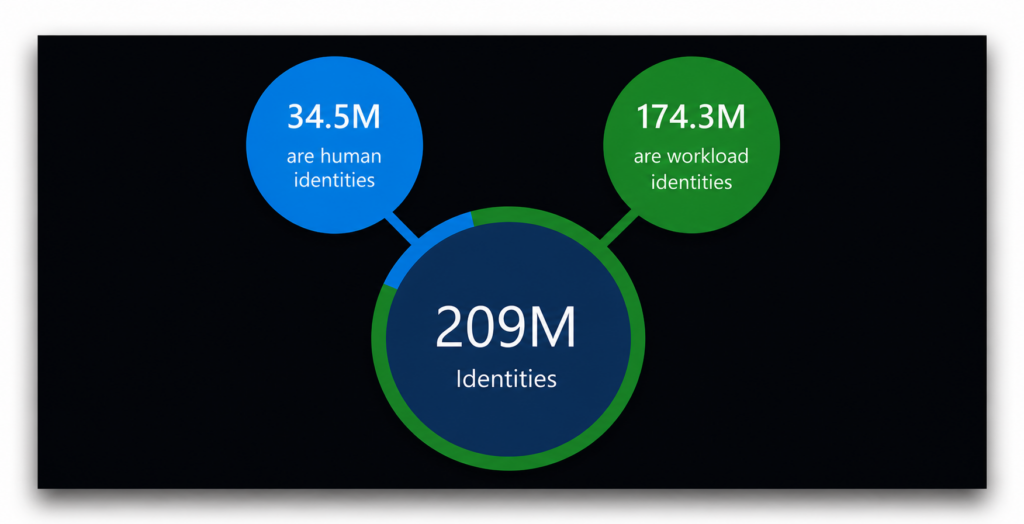
Volume alone would already justify attention. But privilege distribution makes the picture even sharper.
In the same report, Microsoft noted that more than 50% of those 209 million identities were classified as “super identities,” defined simply as “A user or workload identity with access to all permissions and all resources across your entire cloud estate.” This is, indeed, the most super identity there is.
The report further shows that privilege is not concentrated in users. Most of the most powerful identities in the environment are not people, but code.

The next question: What risks do different non-human identities pose?
Non-human identities therefore do not just dominate in count; they also dominate in reach. NHIs can run continuously, authenticate programmatically, and often hold persistent access paths across services and infrastructure. Moreover, they don’t question unusual instructions, and unlike users, nobody logs in every morning to check whether they are behaving as expected.
That’s the landscape that modern cloud environments operate in.
But, before we can reason about the risks introduced by these identities, we first need to understand what they actually are.
The term workload identity is used frequently in Microsoft documentation and security discussions, yet in practice it represents a collection of different identity types that Entra ID exposes under the hood.
Each of these types serves a different operational purpose, follows a different lifecycle, and introduces its own security implications. To understand where Agent Identities fit into this picture, we first need to untangle the taxonomy of workload identities in Entra ID.
For that explanation, read on in the next article: The Taxonomy of Workload Identities in Entra ID: Enterprise Applications, Service Principals, and Other Forms of Organized Confusion
Explore the guide
Jump to the next published chapter in the series—or choose your own adventure.
- Introduction: Understanding and Preventing Entra ID Agent Identity Attacks: A Comprehensive Guide
- Chapter 1: Meet Entra ID Agent Identities (BTW They’re Not People)
- Chapter 2: The Taxonomy of Workload Identities in Entra ID: Enterprise Applications, Service Principals, and Other Forms of Organized Confusion
- Chapter 3: Understanding Microsoft Agent ID and the Agent Identity Platform
- Practice Checkpoint 1: Building Agent ID with MS Graph
- Chapter 4: Agent Identities: Design Deep Dive
- Practice Checkpoint 2: Setting Agent Identity Permissions
- Chapter 5: The Agent Registry and How Agent Identities Operate in Entra ID
- Practice Checkpoint 3: Registering an Agent—With and Without Agent ID
- Practice Checkpoint 4: Verifying Tokens and Claims Across Three Entra ID Authentication Flows
- Chapter 6: Where Things Might Go Wrong with Agent Identities in Entra ID—and How to Prevent Disaster
Endnote
1 This blog focuses on Microsoft Entra ID environments, so we decided to reference most of the data from Microsoft sources. However, similar patterns are observed across the broader industry. For example, the Entro NHI & Secrets Risk Report found that non-human identities outnumber human identities by an average ratio of 144:1 (!) across analyzed enterprise environments, which clearly shows the acceleration in scale at which code-based identities are integrated into modern systems.
