Anmerkung der Redaktion: Willkommen zu Kapitel 1 von „Entra ID-Agenten-Identitätsangriffe verstehen und verhindern: Ein umfassender Leitfaden“. Diese mehrteilige technische Anleitung hilft Ihnen dabei, den Ansatz von Microsoft in Bezug auf Agentenidentitäten zu verstehen und zu erfahren, wie Sie diese vor Angreifern schützen können. Um alle Kapitel und Übungsaufgaben einzusehen, beginnen Sie bitte hier.
Jeder digitale Vorgang, der Systemgrenzen überschreitet, ist nicht mehr nur „Code“. In dem Moment, in dem er auf sinnvolle Weise mit einem anderen System interagieren muss – eine API aufrufen, geschützte Daten lesen oder den Zustand ändern –, muss er eine strukturelle Form annehmen, die andere Systeme erkennen, auswerten und der sie vertrauen können. Diese Form ist eine digitale Identität.
In der Praxis bedeutet dies ein eindeutig identifizierbares, auf einem Verzeichnis basierendes Objekt – ein Sicherheitsprinzipal, dem Berechtigungen erteilt, Rollen zugewiesen, das von Zugriffskontrollmechanismen geprüft und in Prüfprotokollen erfasst werden kann. Code kann Grenzen frei überschreiten, sollte jedoch im Idealfall ohne Rückgriff auf eine Identität keinen Zugriff auf wertvolle Ressourcen erhalten.
Aus diesem Grund ist Identität in verteilten Architekturen nicht nur eine Darstellung oder eine Abstraktionsebene, sondern die Einheit der Steuerung. Systeme tauschen sie aus und stützen ihre Zugriffsentscheidungen darauf, wenn es darauf ankommt: da sie Grenzen überschreitet, über die Laufzeit hinaus fortbesteht, in der sie erstellt wurde, und es ermöglicht, dass digitale Vorgänge außerhalb ihres ursprünglichen elektronischen Kontexts existieren und ausgeführt werden können.
Allgemein lassen sich digitale Identitäten in Microsoft Entra ID (und in den meisten modernen digitalen Ökosystemen) in zwei Kategorien einteilen: menschliche Identitäten und maschinelle – oder nicht-menschliche – Identitäten. Worin besteht der Unterschied?
Menschliche Identitäten stehen für Personen. Mitarbeiter, Mitarbeiter mit Kundenkontakt, Kunden, Berater, Lieferanten und Partner authentifizieren sich in der Regel als Benutzerobjekte. Sie melden sich interaktiv an, werden anhand benutzerorientierter Richtlinien für den bedingten Zugriff überprüft und agieren in der Regel unter einer einzigen primären Identität.
Nicht-menschliche Identitäten (NHIs) bezeichnen – nun ja – alles andere, was innerhalb des Systems agiert und keine Person ist. Diese Identitäten lassen sich grob in zwei Hauptkategorien unterteilen:
- Gerätekennungen, die für Hardware stehen : physische Geräte wie Desktop-Computer, mobile Geräte, IoT-/OT-Sensoren und verwaltete Endpunkte
- „Workload“-Identitäten, die Software-Workloads repräsentieren : Anwendungen, Pipelines, Skripte, Dienstkonten, Bots, Agenten und andere Arten von Automatisierungskonten
Unabhängig von ihrer Art durchlaufen die meisten Identitäten in der digitalen Landschaft denselben stillen Zyklus. Sie authentifizieren sich (sie weisen dem angesprochenen System nach, wer sie zu sein vorgeben); sie werden autorisiert ( das System legt fest, was sie in seinem programmierbaren Kontext tun dürfen); und sie werden erfasst (ihre Aktionen werden protokolliert und sind nachvollziehbar).
Dies ist das klassische AAA-Modell (Authentifizierung, Autorisierung und Abrechnung). Es gilt für alles, für Menschen ebenso wie für Nicht-Menschen. Jede Identität betritt ein System, beantragt Zugriff, führt Aufgaben aus und hinterlässt Spuren.
Dieses Muster kommt Ihnen vielleicht bekannt vor, denn noch bevor wir digitale Systeme entwarfen, haben wir die physische Welt anhand von Identität, Autorität, Verantwortung und – was am wichtigsten ist – Vertrauen strukturiert. Als Entwickler ahmen wir ganz einfach – und vielleicht unbewusst – dieselben Archetypen in der Software nach.
Vielleicht ist die digitale Identität gerade aus diesem Grund zur Steuerungsebene für die damit verbundenen Ressourcen geworden. Folglich stellt die Identität auch die primäre Angriffsfläche für Manipulation, Identitätsbetrug und Missbrauch dar.
Aus diesem Grund bricht der Angreifer, wenn eine digitale Identität kompromittiert wird, nichts im System auf und nimmt auch keine Änderungen daran vor. Stattdessen agiert er innerhalb des Systems unter einer gültigen Identität und bewegt sich mit legitimen Berechtigungsnachweisen und Tokens über softwaredefinierte Grenzen hinweg. Nicht-menschliche Identitäten bilden keine Ausnahme von dieser Dynamik, und in den meisten Umgebungen stellen sie ein umfassenderes und weitaus weniger sichtbares Sicherheitsrisiko dar als menschliche Nutzer.
In diesem Leitfaden befassen wir uns mit einem neuen Typ nicht-menschlicher Identitäten, den Microsoft kürzlich in Entra ID eingeführt hat: Agentenidentitäten.
Dieses Modell wurde entwickelt, um das rasante und gewissermaßen unaufhaltsame Wachstum von KI-Agenten und der breiter gefassten Klasse von Automatisierungs-Workloads zu unterstützen, und erweitert die seit Langem etablierten Architekturen für Service-Principals, Anwendungen und Benutzer auf einen neuen Betriebsbereich.
Um zu verstehen, warum dies von Bedeutung ist, müssen wir zunächst einen Schritt zurücktreten und uns vor Augen führen, dass es sich bei den meisten Identitäten, die in modernen Cloud-Umgebungen zum Einsatz kommen, gar nicht um Menschen handelt.
Warum nicht-menschliche Identitäten tatsächlich wichtiger sind als Nutzer
In der Sicherheitsbranche herrscht seit langem die Annahme, dass Benutzerkonten die Kronjuwelen sind, die vor allem anderen geschützt werden müssen. Dieser Instinkt war sinnvoll, als Menschen noch die Hauptakteure in digitalen Systemen waren. Sobald jedoch die Identität zur Steuerungsebene wird und sich immer mehr Software-Integrationen im gesamten Ökosystem des Internets ausbreiten, wird der Umfang zum entscheidenden Faktor für das Risiko.
Im „State of Multicloud Security Report 2024“ von Microsoft wird dieses Ausmaß deutlich sichtbar. In dem Bericht heißt es:
„Da immer mehr Unternehmen ihre Workloads in die Cloud verlagern, beobachten wir einen rasanten Anstieg der Anzahl der neu erstellten Workload-Identitäten. Derzeit kommt auf zehn Workload-Identitäten eine menschliche Identität. Dieses Problem ist bei kleinen und mittleren Unternehmen noch ausgeprägter: Dort kommt auf 50 Workload-Identitäten eine menschliche Identität.“
In den im Jahr 2023 analysierten Kundenumgebungen identifizierte Entra Permissions Management 209 Millionen Cloud-Identitäten. Mehr als 83 % davon waren nicht-menschlicher Natur.
Und das war im Jahr 2023.
Seitdem ist die Zahl der nicht-menschlichen Identitäten aufgrund der zunehmenden Verbreitung cloud-nativer Architekturen, groß angelegter Integrationen und der raschen Einführung KI-gesteuerter Automatisierungen dramatisch gestiegen.1
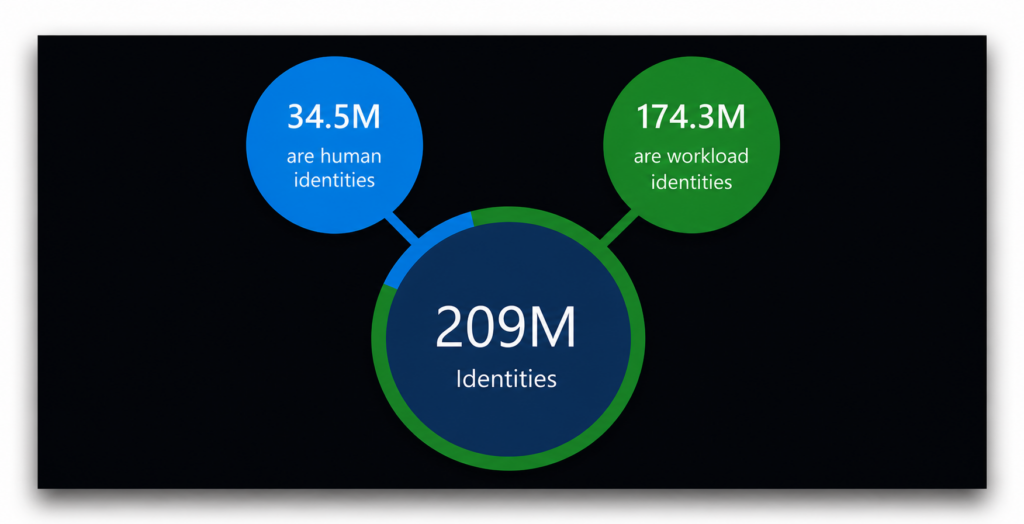
Schon allein der Umfang würde Beachtung rechtfertigen. Doch die Verteilung der Privilegien lässt das Bild noch deutlicher hervortreten.
In demselben Bericht stellte Microsoft fest, dass mehr als 50 % dieser 209 Millionen Identitäten als „Super-Identitäten“ eingestuft wurden, die einfach definiert sind als „eine Benutzer- oder Workload-Identität mit Zugriff auf alle Berechtigungen und alle Ressourcen in Ihrer gesamten Cloud-Umgebung“. Dies ist in der Tat die „supereste“ Identität, die es gibt.
Der Bericht zeigt ferner, dass sich die Berechtigungen nicht auf die Benutzer konzentrieren. Die meisten der einflussreichsten Identitäten in der Umgebung sind keine Personen, sondern Code.

Die nächste Frage: Welche Risiken gehen von verschiedenen nicht-menschlichen Identitäten aus?
Nicht-menschliche Identitäten dominieren daher nicht nur zahlenmäßig, sondern auch hinsichtlich ihrer Reichweite. Nicht-menschliche Identitäten können kontinuierlich laufen, sich programmgesteuert authentifizieren und verfügen oft über dauerhafte Zugriffspfade über Dienste und Infrastruktur hinweg. Darüber hinaus hinterfragen sie ungewöhnliche Anweisungen nicht, und im Gegensatz zu Benutzern meldet sich niemand jeden Morgen an, um zu überprüfen, ob sie sich wie erwartet verhalten.
Das ist das Umfeld, in dem moderne Cloud-Umgebungen betrieben werden.
Bevor wir jedoch die mit diesen Identitäten verbundenen Risiken erörtern können, müssen wir zunächst verstehen, worum es sich dabei eigentlich handelt.
Der Begriff „Workload-Identität“ wird in der Microsoft-Dokumentation und in Sicherheitsdiskussionen häufig verwendet, doch in der Praxis bezeichnet er eine Sammlung verschiedener Identitätstypen, die Entra ID im Hintergrund bereitstellt.
Jeder dieser Typen erfüllt einen anderen betrieblichen Zweck, durchläuft einen anderen Lebenszyklus und bringt eigene sicherheitsrelevante Auswirkungen mit sich. Um zu verstehen, wo sich Agent-Identitäten in dieses Gesamtbild einfügen, müssen wir zunächst die Taxonomie der Workload-Identitäten in Entra ID entwirren.
Eine Erläuterung hierzu finden Sie im nächsten Artikel: Die Taxonomie der Workload-Identitäten in Entra ID: Unternehmensanwendungen, Service-Principals und andere Formen organisierter Verwirrung
Entdecken Sie den Leitfaden
Springen Sie zum nächsten veröffentlichten Kapitel der Reihe – oder wählen Sie Ihr eigenes Abenteuer.
- Einleitung: Entra ID Agent-Identitätsangriffe verstehen und verhindern: Ein umfassender Leitfaden
- Kapitel 1: Lernen Sie die Identitäten der Entra-ID-Agenten kennen (übrigens: Es handelt sich dabei nicht um Personen)
- Kapitel 2: Die Taxonomie von Workload-Identitäten in Entra ID: Unternehmensanwendungen, Service-Principals und andere Formen organisierter Verwirrung
- Kapitel 3: Einführung in die Microsoft Agent-ID und die Agent Identity Platform
- Übungs-Checkpunkt 1: Erstellen einer Agenten-ID mit MS Graph
- Kapitel 4: Agentenidentitäten: Ein tiefer Einblick in das Design
- Übungs-Checkpunkt 2: Festlegen der Berechtigungen für die Agentenidentität
- Kapitel 5: Das Agentenregister und die Funktionsweise von Agentenidentitäten in Entra ID
- Übungsschritt 3: Registrierung eines Agenten – mit und ohne Agenten-ID
- Praxis-Checkpunkt 4: Überprüfung von Tokens und Claims in drei Entra-ID-Authentifizierungsabläufen
- Kapitel 6: Wo es bei den Agentenidentitäten in Entra ID zu Problemen kommen könnte – und wie man eine Katastrophe verhindert
Endnote
1 Da sich dieser Blog auf Microsoft Entra ID-Umgebungen konzentriert, haben wir uns entschlossen, den Großteil der Daten aus Microsoft-Quellen zu beziehen. Ähnliche Muster lassen sich jedoch branchenweit beobachten. So ergab beispielsweise der „Entra NHI & Secrets Risk Report“, dass in den analysierten Unternehmensumgebungen die Anzahl der nicht-menschlichen Identitäten die der menschlichen Identitäten im Durchschnitt im Verhältnis von 144:1 (!) übersteigt, was deutlich zeigt, wie rasant die Integration code-basierter Identitäten in moderne Systeme voranschreitet.
