Nota do editor: Bem-vindo ao Capítulo 1 de «Compreender e prevenir ataques à identidade do agente do Entra ID: Um guia abrangente». Este guia técnico, dividido em várias partes, ajuda-o a compreender a abordagem da Microsoft em relação às identidades dos agentes e como pode protegê-las contra agentes maliciosos. Para consultar todos os capítulos e lições práticas, comece aqui.
Qualquer operação digital que ultrapasse os limites de um sistema deixa de ser apenas «código». No momento em que precisa de interagir com outro sistema de forma significativa — chamar uma API, ler dados protegidos ou modificar o estado —, tem de assumir uma forma estrutural que outros sistemas possam reconhecer, avaliar e na qual possam confiar. Essa forma é uma identidade digital.
Na prática, isto significa um objeto identificável, baseado num diretório — uma entidade de segurança à qual podem ser concedidas permissões, atribuídas funções, avaliada por mecanismos de controlo de acesso e registada em registos de auditoria. O código pode atravessar limites livremente, mas, idealmente, não pode aceder a nada de valor sem o fazer através de uma identidade.
Por esta razão, nas arquiteturas distribuídas, a identidade não é apenas uma representação ou uma camada de abstração, mas sim a unidade de controlo. Os sistemas trocam-na e baseiam nela as decisões de acesso quando isso é relevante: à medida que atravessa fronteiras, persiste para além do tempo de execução que a criou e permite que as operações digitais existam e sejam executadas fora do seu contexto eletrónico original.
Em termos gerais, as identidades digitais no Microsoft Entra ID (e na maioria dos ecossistemas digitais modernos) dividem-se em duas categorias: identidades humanas e identidades de máquinas — ou não humanas. Qual é a diferença?
As identidades humanas representam pessoas. Colaboradores, trabalhadores da linha da frente, clientes, consultores, fornecedores e parceiros costumam autenticar-se como objetos de utilizador. Iniciam sessão de forma interativa, são avaliados por políticas de Acesso Condicional centradas no utilizador e, normalmente, operam sob uma única identidade principal.
As identidades não humanas (NHIs) representam, basicamente, tudo o resto que opera dentro do sistema e que não é uma pessoa. Estas identidades podem ser divididas, de forma geral, em duas categorias principais:
- Identidades de dispositivos, que representam o hardware: dispositivos físicos , tais como computadores de secretária, dispositivos móveis, sensores de IoT/OT e terminais geridos
- Identidades de «carga de trabalho», que representam cargas de trabalho de software: aplicações, pipelines, scripts, contas de serviço, bots, agentes e outros tipos de contas de automatização
Independentemente do tipo, a maioria das identidades passa pelo mesmo ciclo discreto no panorama digital. São autenticadas (comprovam ao sistema a quem se dirigem quem afirmam ser); são autorizadas ( o sistema determina o que lhes é permitido fazer no seu contexto programável); e são registadas (as suas ações são registadas e rastreáveis).
Este é o modelo clássico de Autenticação, Autorização e Contabilização (AAA). Aplica-se a tudo, tanto a seres humanos como a não humanos. Cada identidade entra num sistema, solicita acesso, realiza tarefas e deixa um rasto para trás.
Este padrão pode parecer-nos familiar porque, pouco antes de começarmos a conceber sistemas digitais, estruturámos o mundo físico em torno da identidade, da autoridade, da responsabilidade e, acima de tudo, da confiança. Enquanto programadores, simplesmente — e talvez inconscientemente — reproduzimos esses mesmos arquétipos no software.
Talvez por essa razão, a identidade digital tenha-se tornado o plano de controlo dos recursos que a rodeiam. Consequentemente, a identidade é também a principal superfície de ataque para manipulação, suplantação de identidade e uso indevido.
É por isso que, quando uma identidade digital é comprometida, o atacante não invade nem altera nada no sistema. Em vez disso, opera no seu interior sob a identidade de um utilizador válido, atravessando limites definidos por software com afirmações e tokens legítimos. As identidades não humanas não são exceção a esta dinâmica e, na maioria dos ambientes, representam uma exposição mais ampla e muito menos visível do que os utilizadores humanos.
Neste guia, analisamos um novo tipo de identidade não humana que a Microsoft introduziu recentemente no Entra ID: as identidades de agente.
Concebido para dar resposta ao crescimento rápido e, de certa forma, incessante dos agentes de IA e da classe mais ampla de cargas de trabalho de automatização, este modelo alarga as arquiteturas de longa data de Entidade de Serviço, Aplicação e Utilizador a um novo domínio operacional.
Para compreender por que razão isto é importante, temos primeiro de dar um passo atrás e perceber que a maioria das identidades que operam em ambientes de nuvem modernos não são, de todo, pessoas.
Por que razão as identidades não humanas são, na verdade, mais importantes do que os utilizadores
Existe um pressuposto, herdado da era digital antiga, no domínio da segurança, segundo o qual as contas de utilizador são as joias da coroa que devem ser protegidas acima de tudo. Esse instinto fazia sentido quando os seres humanos eram os principais intervenientes nos sistemas digitais. Mas, à medida que a identidade se torna o plano de controlo e que cada vez mais integrações de software se propagam pelo ecossistema da Internet, a escala passa a ser o fator que define o risco.
No Relatório da Microsoft sobre o Estado da Segurança Multicloud de 2024, essa dimensão torna-se muito evidente. O relatório afirma:
«À medida que cada vez mais empresas transferem as suas cargas de trabalho para a nuvem, assistimos a um rápido crescimento do número de identidades de cargas de trabalho criadas. Atualmente, existe uma identidade humana por cada 10 identidades de cargas de trabalho. Este problema é ainda mais grave entre as pequenas e médias empresas, que têm uma identidade humana por cada 50 identidades de cargas de trabalho.»
Nos ambientes dos clientes analisados em 2023, o Entra Permissions Management identificou 209 milhões de identidades na nuvem. Mais de 83 % delas não eram humanas.
E isso foi em 2023.
Desde então, com a aceleração das arquiteturas nativas da nuvem, as integrações em grande escala e a rápida adoção de automatizações baseadas em IA, o número de identidades não humanas aumentou drasticamente.1
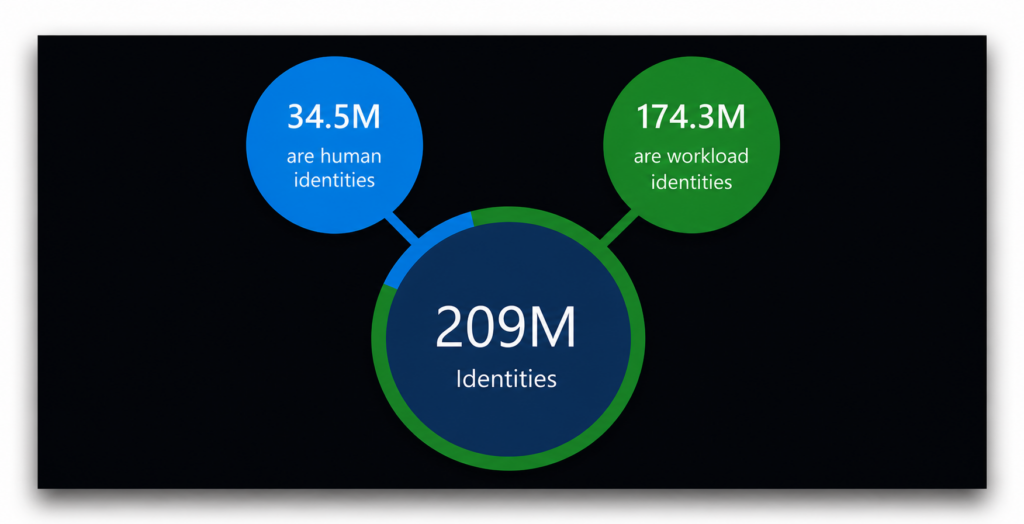
O volume, por si só, já justificaria a atenção. Mas a distribuição dos privilégios torna o quadro ainda mais nítido.
No mesmo relatório, a Microsoft referiu que mais de 50 % dessas 209 milhões de identidades foram classificadas como «superidentidades», definidas simplesmente como «uma identidade de utilizador ou de carga de trabalho com acesso a todas as permissões e a todos os recursos em todo o seu ambiente de nuvem». Esta é, de facto, a superidentidade por excelência.
O relatório revela ainda que os privilégios não se concentram nos utilizadores. A maioria das identidades mais poderosas no ambiente não são pessoas, mas sim código.

A próxima questão: Que riscos representam as diferentes identidades não humanas?
As identidades não humanas, portanto, não se limitam a dominar em número; dominam também em alcance. As NHIs podem funcionar de forma contínua, autenticar-se programaticamente e, muitas vezes, dispõem de vias de acesso persistentes entre serviços e infraestruturas. Além disso, não questionam instruções invulgares e, ao contrário dos utilizadores, ninguém inicia sessão todas as manhãs para verificar se estão a comportar-se conforme o esperado.
É nesse contexto que os ambientes modernos na nuvem funcionam.
No entanto, antes de podermos analisar os riscos decorrentes destas identidades, temos primeiro de compreender o que elas realmente são.
O termo «identidade de carga de trabalho» é utilizado com frequência na documentação da Microsoft e em debates sobre segurança; no entanto, na prática, representa um conjunto de diferentes tipos de identidade que o Entra ID disponibiliza nos bastidores.
Cada um destes tipos tem uma finalidade operacional diferente, segue um ciclo de vida distinto e acarreta as suas próprias implicações em termos de segurança. Para compreender onde é que as Identidades de Agente se enquadram neste contexto, precisamos primeiro de esclarecer a taxonomia das identidades de cargas de trabalho no Entra ID.
Para obter essa explicação, continue a ler no próximo artigo: A taxonomia das identidades de carga de trabalho no Entra ID: aplicações empresariais, entidades de serviço e outras formas de confusão organizada
Explore o guia
Passa para o próximo capítulo publicado da série — ou escolhe a tua própria aventura.
- Introdução: Compreender e prevenir ataques à identidade do agente Entra ID: Um guia completo
- Capítulo 1: Conheça as identidades dos agentes da Entra ID (a propósito, não são pessoas)
- Capítulo 2: A taxonomia das identidades de carga de trabalho no Entra ID: aplicações empresariais, entidades de serviço e outras formas de confusão organizada
- Capítulo 3: Compreender o Microsoft Agent ID e a Plataforma de Identidade do Agente
- Ponto de verificação 1: Criação de um ID de agente com o MS Graph
- Capítulo 4: Identidades dos agentes: análise aprofundada do design
- Ponto de verificação 2: Definição das permissões de identidade do agente
- Capítulo 5: O Registo de Agentes e o Funcionamento das Identidades dos Agentes no Entra ID
- Ponto de verificação 3: Registo de um agente — com e sem ID de agente
- Ponto de verificação 4: Verificação de tokens e reivindicações em três fluxos de autenticação do Entra ID
- Capítulo 6: Onde as coisas podem correr mal com as identidades dos agentes no Entra ID — e como evitar o desastre
Nota final
1 Este blogue centra-se nos ambientes do Microsoft Entra ID, pelo que decidimos basear-nos principalmente em dados provenientes de fontes da Microsoft. No entanto, observam-se padrões semelhantes em todo o setor. Por exemplo, o Relatório de Risco de Identidades Não Humanas e Segredos da Entra revelou que as identidades não humanas superam as identidades humanas numa proporção média de 144:1 (!) nos ambientes empresariais analisados, o que demonstra claramente a aceleração na escala a que as identidades baseadas em código estão a ser integradas nos sistemas modernos.
