Nota dell'editore: Benvenuti al Capitolo 1 di “Comprendere e prevenire gli attacchi alle identità degli agenti Entra ID: una guida completa”. Questa guida tecnica in più parti vi aiuta a comprendere l’approccio di Microsoft alle identità degli agenti e come proteggerle dagli autori delle minacce. Per consultare tutti i capitoli e le lezioni pratiche, iniziate da qui.
Qualsiasi operazione digitale che superi i confini di un sistema smette di essere semplicemente “codice”. Nel momento in cui deve interagire con un altro sistema in modo significativo — chiamare un’API, leggere dati protetti o modificare uno stato — deve assumere una forma strutturale che gli altri sistemi possano riconoscere, valutare e considerare affidabile. Tale forma è un’ identità digitale.
In pratica, ciò significa un oggetto identificabile associato a una directory: un soggetto di sicurezza a cui è possibile concedere autorizzazioni, assegnare ruoli, che può essere valutato dai meccanismi di controllo degli accessi e registrato nei registri di audit. Il codice può attraversare liberamente i confini, ma idealmente non può accedere a nulla di valore senza farlo tramite un’identità.
Per questo motivo, nelle architetture distribuite, l’identità non è solo una rappresentazione o un livello di astrazione, ma l’unità di controllo. I sistemi la scambiano e basano su di essa le decisioni di accesso quando è necessario: poiché attraversa i confini, persiste oltre il runtime che l’ha creata e consente alle operazioni digitali di esistere e funzionare al di fuori del loro contesto elettronico originario.
A grandi linee, le identità digitali in Microsoft Entra ID (e nella maggior parte degli ecosistemi digitali moderni) si dividono in due categorie: identità umane e identità di macchine — o non umane. Qual è la differenza?
Le identità umane rappresentano le persone. Dipendenti, operatori in prima linea, clienti, consulenti, fornitori e partner vengono solitamente autenticati come oggetti utente. Effettuano l'accesso in modo interattivo, vengono valutati in base a criteri di accesso condizionato incentrati sull'utente e, di norma, operano con un'unica identità primaria.
Le identità non umane (NHI) rappresentano, in sostanza, tutto ciò che opera all’interno del sistema e che non è una persona. Queste identità possono essere suddivise, in linea di massima, in due categorie principali:
- Identità dei dispositivi, che rappresentano l'hardware: dispositivi fisici quali computer desktop, dispositivi mobili, sensori IoT/OT ed endpoint gestiti
- Identità “Workload”, che rappresentano i carichi di lavoro software: applicazioni, pipeline, script, account di servizio, bot, agenti e altri tipi di account di automazione
Indipendentemente dal tipo, la maggior parte delle identità segue lo stesso ciclo silenzioso nel panorama digitale. Esse vengono autenticate (dimostrano al sistema a cui si rivolgono chi dichiarano di essere); vengono autorizzate ( il sistema determina cosa sono autorizzate a fare nel proprio contesto programmabile); e vengono registrate (le loro azioni vengono registrate e sono tracciabili).
Si tratta del classico modello di autenticazione, autorizzazione e contabilità (AAA). Si applica a tutto, sia agli esseri umani che ai non umani. Ogni identità accede a un sistema, richiede l’accesso, svolge un’attività e lascia una traccia.
Questo schema potrebbe sembrarvi familiare perché, non molto tempo prima di progettare sistemi digitali, abbiamo strutturato il mondo fisico attorno a concetti quali identità, autorità, responsabilità e, soprattutto, fiducia. In qualità di sviluppatori, emuliamo semplicemente, e forse inconsciamente, gli stessi archetipi nel software.
Forse proprio per questo motivo, l’identità digitale è diventata il piano di controllo delle risorse che la circondano. Di conseguenza, l’identità rappresenta anche la principale superficie di attacco per la manipolazione, l’usurpazione d’identità e l’uso improprio.
Ecco perché, quando un’identità digitale viene compromessa, l’autore dell’attacco non manomette né modifica nulla nel sistema. Al contrario, opera al suo interno sotto l’identità di un soggetto valido, muovendosi attraverso i confini definiti dal software con asserzioni e token legittimi. Le identità non umane non fanno eccezione a questa dinamica e, nella maggior parte degli ambienti, rappresentano un’esposizione più ampia e di gran lunga meno visibile rispetto agli utenti umani.
In questa guida analizziamo un nuovo tipo di identità non umana che Microsoft ha recentemente introdotto in Entra ID: le identità degli agenti.
Progettato per supportare la crescita rapida e in qualche modo inarrestabile degli agenti di intelligenza artificiale e della più ampia categoria di carichi di lavoro di automazione, questo modello estende le consolidate architetture di Service Principal, Applicazione e Utente a un nuovo ambito operativo.
Per capire perché questo sia importante, dobbiamo innanzitutto fare un passo indietro e renderci conto che la maggior parte delle identità presenti nei moderni ambienti cloud non sono affatto persone.
Perché le identità non umane contano in realtà più degli utenti
Nel campo della sicurezza esiste un preconcetto, radicato nel mondo digitale, secondo cui gli account utente sono il tesoro più prezioso che va protetto a tutti i costi. Questo approccio aveva senso quando gli esseri umani erano gli attori principali nei sistemi digitali. Ma ora che l’identità è diventata il piano di controllo e che sempre più integrazioni software si diffondono nell’ecosistema di Internet, è la scala a determinare il rischio.
Nel rapporto di Microsoft del 2024 sullo stato della sicurezza multicloud, tale portata risulta molto evidente. Il rapporto afferma:
“Man mano che sempre più aziende trasferiscono i propri carichi di lavoro sul cloud, assistiamo a una rapida crescita del numero di identità di carico di lavoro create. Oggi, c’è un’identità umana ogni 10 identità di carico di lavoro. Il problema è ancora più grave tra le piccole e medie imprese, dove si registra un’identità umana ogni 50 identità di carico di lavoro.”
Negli ambienti dei clienti analizzati nel 2023, Entra Permissions Management ha individuato 209 milioni di identità cloud. Oltre l’83% di queste era di natura non umana.
E quello era il 2023.
Da allora, con l’accelerazione delle architetture cloud-native, delle integrazioni su larga scala e della rapida diffusione delle automazioni basate sull’intelligenza artificiale, il numero di identità non umane è aumentato in modo esponenziale.1
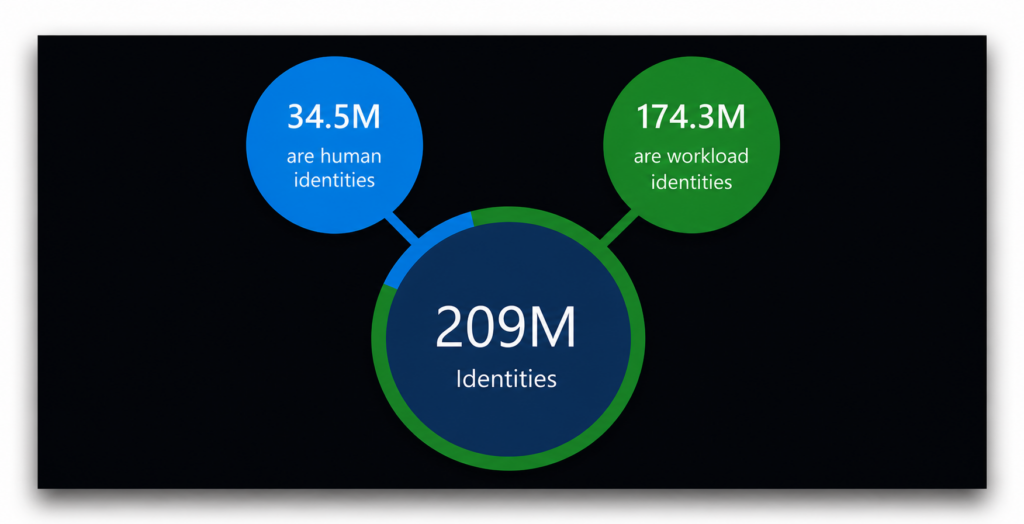
Già solo il volume giustificherebbe di per sé l'attenzione. Ma la distribuzione dei privilegi rende il quadro ancora più nitido.
Nello stesso rapporto, Microsoft ha osservato che oltre il 50% di quei 209 milioni di identità era classificato come “super identità”, definita semplicemente come “un’identità utente o di carico di lavoro con accesso a tutte le autorizzazioni e a tutte le risorse dell’intero ambiente cloud”. Si tratta, infatti, della super identità per eccellenza.
Il rapporto evidenzia inoltre che i privilegi non sono concentrati negli utenti. La maggior parte delle identità più potenti nell’ambiente non sono persone, bensì codice.

La domanda successiva: quali rischi comportano le diverse identità non umane?
Le identità non umane, quindi, non solo prevalgono in termini di numero, ma anche in termini di portata. Le NHI possono funzionare in modo continuo, effettuare l’autenticazione a livello di programmazione e spesso dispongono di percorsi di accesso persistenti attraverso i servizi e l’infrastruttura. Inoltre, non mettono in discussione le istruzioni insolite e, a differenza degli utenti, nessuno effettua l’accesso ogni mattina per verificare se si comportano come previsto.
Questo è il contesto in cui operano i moderni ambienti cloud.
Ma, prima di poter valutare i rischi derivanti da queste identità, dobbiamo innanzitutto capire di cosa si tratti effettivamente.
Il termine "identità del carico di lavoro" viene utilizzato frequentemente nella documentazione Microsoft e nelle discussioni sulla sicurezza, ma in pratica rappresenta un insieme di diversi tipi di identità che Entra ID rende disponibili "dietro le quinte".
Ciascuno di questi tipi ha una finalità operativa diversa, segue un ciclo di vita diverso e comporta implicazioni specifiche in termini di sicurezza. Per comprendere quale sia il ruolo delle identità degli agenti in questo contesto, dobbiamo innanzitutto fare chiarezza sulla tassonomia delle identità dei carichi di lavoro in Entra ID.
Per saperne di più, continua a leggere nel prossimo articolo: La tassonomia delle identità dei carichi di lavoro in Entra ID: applicazioni aziendali, entità di servizio e altre forme di confusione organizzata
Scopri la guida
Passa al prossimo capitolo pubblicato della serie oppure scegli la tua avventura.
- Introduzione: Comprendere e prevenire gli attacchi all’identità degli agenti Entra ID: una guida completa
- Capitolo 1: Scopri le identità degli agenti di Entra ID (a proposito, non sono persone)
- Capitolo 2: La tassonomia delle identità dei carichi di lavoro in Entra ID: applicazioni aziendali, entità di servizio e altre forme di confusione organizzata
- Capitolo 3: Approfondimento sull’ID di Microsoft Agent e sulla piattaforma di identità degli agenti
- Punto di controllo 1 dell'esercitazione: Creazione dell'ID agente con MS Graph
- Capitolo 4: Identità degli agenti: approfondimento sul design
- Punto di verifica 2: Impostazione delle autorizzazioni relative all’identità dell’agente
- Capitolo 5: Il registro degli agenti e il funzionamento delle identità degli agenti in Entra ID
- Punto di controllo 3: Registrazione di un agente — con e senza ID agente
- Punto di controllo 4: Verifica dei token e delle affermazioni nei tre flussi di autenticazione di Entra ID
- Capitolo 6: Dove potrebbero sorgere problemi con le identità degli agenti in Entra ID e come evitare il disastro
Nota finale
1 Questo blog è incentrato sugli ambienti Microsoft Entra ID, pertanto abbiamo deciso di attingere la maggior parte dei dati da fonti Microsoft. Tuttavia, si osservano tendenze simili in tutto il settore. Ad esempio, il rapporto Entro NHI & Secrets Risk Report ha rilevato che, negli ambienti aziendali analizzati, le identità non umane superano quelle umane con un rapporto medio di 144:1 (!) , il che dimostra chiaramente l’accelerazione con cui le identità basate su codice vengono integrate nei sistemi moderni.
