Note de la rédaction: Bienvenue dans le chapitre 1 de « Comprendre et prévenir les attaques ciblant l’identité des agents Entra ID : guide complet ». Ce guide technique en plusieurs parties vous aide à comprendre l’approche de Microsoft en matière d’identités d’agents et à découvrir comment vous pouvez les protéger contre les acteurs malveillants. Pour consulter tous les chapitres et les exercices pratiques, commencez ici.
Toute opération numérique qui dépasse les limites d’un système cesse d’être simplement du « code ». Dès lors qu’elle doit interagir de manière significative avec un autre système — appeler une API, lire des données protégées ou modifier un état —, elle doit prendre une forme structurelle que les autres systèmes peuvent reconnaître, évaluer et à laquelle ils peuvent faire confiance. Cette forme est une identité numérique.
Concrètement, cela signifie un objet identifiable associé à un répertoire : une entité de sécurité à laquelle on peut accorder des autorisations, attribuer des rôles, qui peut être évaluée par des mécanismes de contrôle d’accès et dont les actions sont consignées dans des journaux d’audit. Le code peut franchir librement les frontières, mais, dans l’idéal, il ne doit pas pouvoir accéder à des ressources de valeur sans passer par une identité.
C'est pourquoi, dans les architectures distribuées, l'identité n'est pas seulement une représentation ou une couche d'abstraction, mais bien l'unité de contrôle. Les systèmes l'échangent et s'appuient sur elle pour prendre des décisions d'accès lorsque cela s'avère nécessaire : en effet, elle franchit les frontières, perdure au-delà de l'environnement d'exécution qui l'a créée et permet aux opérations numériques d'exister et de fonctionner en dehors de leur contexte électronique d'origine.
D'une manière générale, les identités numériques dans Microsoft Entra ID (ainsi que dans la plupart des écosystèmes numériques modernes) se répartissent en deux catégories : les identités humaines et les identités machines — ou non humaines. Quelle est la différence ?
Les identités humaines correspondent à des personnes. Les employés, les agents de première ligne, les clients, les consultants, les fournisseurs et les partenaires s'authentifient généralement en tant qu'objets utilisateur. Ils se connectent de manière interactive, sont soumis à des politiques d'accès conditionnel axées sur l'utilisateur et opèrent généralement sous une seule identité principale.
Les identités non humaines (NHI) désignent, en somme, tout ce qui opère au sein du système et qui n'est pas une personne. Ces identités peuvent être globalement classées en deux grandes catégories :
- Les identités des appareils, qui correspondent au matériel : appareils physiques tels que les ordinateurs de bureau, les appareils mobiles, les capteurs IoT/OT et les terminaux gérés
- Les identités « Workload », qui représentent les charges de travail logicielles : applications, pipelines, scripts, comptes de service, bots, agents et autres types de comptes d’automatisation
Quel que soit leur type, la plupart des identités suivent le même cycle discret dans l'environnement numérique. Elles s'authentifient (elles prouvent au système auquel elles s'adressent qu'elles sont bien celles qu'elles prétendent être) ; elles sont autorisées ( le système détermine ce qu'elles sont autorisées à faire dans son contexte programmable) ; et elles sont prises en compte (leurs actions sont enregistrées et traçables).
Il s'agit du modèle classique d'authentification, d'autorisation et de comptabilité (AAA). Il s'applique à tout, qu'il s'agisse d'êtres humains ou non. Chaque identité accède à un système, demande un accès, effectue une tâche et laisse une trace derrière elle.
Ce schéma vous semble peut-être familier, car bien avant de concevoir des systèmes numériques, nous avions déjà structuré le monde physique autour de l’identité, de l’autorité, de la responsabilité et, surtout, de la confiance. En tant que développeurs, nous reproduisons simplement, et peut-être inconsciemment, ces mêmes archétypes dans les logiciels.
C'est peut-être pour cette raison que l'identité numérique est devenue le plan de contrôle des ressources qui l'entourent. Par conséquent, l'identité constitue également la principale surface d'attaque pour la manipulation, l'usurpation d'identité et les utilisations abusives.
C’est pourquoi, lorsqu’une identité numérique est compromise, l’attaquant ne pirate ni ne modifie quoi que ce soit dans le système. Au contraire, il opère au sein de celui-ci sous l’identité d’un utilisateur valide, franchissant les frontières définies par les logiciels à l’aide d’assertions et de jetons légitimes. Les identités non humaines ne font pas exception à cette dynamique et, dans la plupart des environnements, elles représentent une vulnérabilité plus étendue et bien moins visible que celle des utilisateurs humains.
Dans ce guide, nous nous intéressons à un nouveau type d'identité non humaine que Microsoft a récemment introduit dans Entra ID : les identités d'agent.
Conçu pour accompagner la croissance rapide et quelque peu effrénée des agents d'IA et, plus largement, des charges de travail liées à l'automatisation, ce modèle étend les architectures bien établies de « Service Principal », d'« Application » et d'« Utilisateur » à un nouveau domaine opérationnel.
Pour comprendre pourquoi cela est important, il faut d’abord prendre un peu de recul et réaliser que la plupart des identités présentes dans les environnements cloud modernes ne correspondent pas du tout à des personnes.
Pourquoi les identités non humaines ont en réalité plus d'importance que les utilisateurs
Dans le domaine de la sécurité, il existe une idée reçue selon laquelle les comptes utilisateurs seraient les « joyaux de la couronne » qu’il faut protéger par-dessus tout. Cet instinct se justifiait lorsque les êtres humains étaient les principaux acteurs des systèmes numériques. Mais dès lors que l’identité devient le plan de contrôle et que de plus en plus d’intégrations logicielles se multiplient dans l’écosystème d’Internet, c’est l’échelle qui définit désormais le risque.
Dans le rapport 2024 de Microsoft intitulé « État de la sécurité multicloud », cette ampleur apparaît très clairement. Le rapport indique :
« Alors que de plus en plus d’entreprises transfèrent leurs charges de travail vers le cloud, nous constatons une croissance rapide du nombre d’identités de charges de travail créées. Aujourd’hui, on compte une identité humaine pour dix identités de charges de travail. Ce problème est encore plus aigu parmi les petites et moyennes entreprises, qui affichent un ratio d’une identité humaine pour cinquante identités de charges de travail. »
Dans l'ensemble des environnements clients analysés en 2023, Entra Permissions Management a recensé 209 millions d'identités cloud. Plus de 83 % d'entre elles n'étaient pas humaines.
C'était en 2023.
Depuis lors, avec l'essor des architectures « cloud-native », les intégrations à grande échelle et l'adoption rapide d'automatisations basées sur l'IA, le nombre d'identités non humaines a considérablement augmenté.1
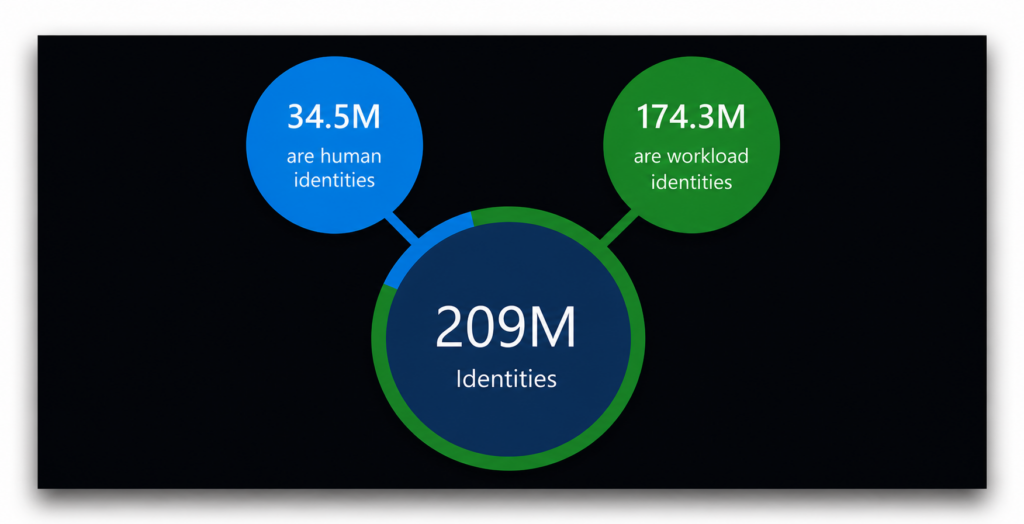
Le volume à lui seul suffirait déjà à justifier qu'on s'y intéresse. Mais la répartition des privilèges rend le tableau encore plus saisissant.
Dans ce même rapport, Microsoft a souligné que plus de 50 % de ces 209 millions d’identités étaient classées comme des « super-identités », définies simplement comme « une identité d’utilisateur ou de charge de travail disposant d’un accès à l’ensemble des autorisations et de toutes les ressources de l’ensemble de votre infrastructure cloud ». Il s’agit en effet de la « super-identité » par excellence.
Le rapport montre en outre que les privilèges ne sont pas concentrés entre les mains des utilisateurs. La plupart des identités les plus puissantes de l'environnement ne sont pas des personnes, mais du code.

Question suivante : quels risques présentent les différentes identités non humaines ?
Les identités non humaines ne dominent donc pas seulement en nombre ; elles dominent également en termes de portée. Elles peuvent fonctionner en continu, s’authentifier de manière programmatique et disposent souvent de chemins d’accès persistants à travers les services et l’infrastructure. De plus, elles ne remettent pas en question les instructions inhabituelles et, contrairement aux utilisateurs, personne ne se connecte chaque matin pour vérifier si elles se comportent comme prévu.
C'est dans ce contexte que s'inscrivent les environnements cloud modernes.
Mais avant de pouvoir analyser les risques liés à ces identités, nous devons d'abord comprendre en quoi elles consistent réellement.
Le terme « identité de charge de travail » est fréquemment utilisé dans la documentation Microsoft et les débats sur la sécurité ; pourtant, dans la pratique, il désigne un ensemble de différents types d’identités qu’Entra ID met à disposition en arrière-plan.
Chacun de ces types répond à un objectif opérationnel différent, suit un cycle de vie distinct et comporte ses propres implications en matière de sécurité. Pour comprendre la place qu’occupent les identités d’agent dans ce contexte, nous devons d’abord clarifier la taxonomie des identités de charges de travail dans Entra ID.
Pour en savoir plus, consultez l'article suivant : « La taxonomie des identités de charge de travail dans Entra ID : applications d'entreprise, entités de service et autres formes de confusion organisée »
Découvrez le guide
Passez au prochain chapitre publié de la série… ou choisissez votre propre aventure.
- Introduction : Comprendre et prévenir les attaques d'usurpation d'identité de l'agent Entra ID : un guide complet
- Chapitre 1 : Découvrez les identités des agents d’Entra ID (au fait, ce ne sont pas des personnes)
- Chapitre 2 : La taxonomie des identités de charge de travail dans Entra ID : applications d’entreprise, entités de service et autres formes de confusion organisée
- Chapitre 3 : Comprendre l'identifiant Microsoft Agent et la plateforme d'identité Agent
- Point de contrôle n° 1 : Création d'un identifiant d'agent avec MS Graph
- Chapitre 4 : Identités des agents : analyse approfondie de la conception
- Point de contrôle n° 2 : Configuration des autorisations d’identité des agents
- Chapitre 5 : Le registre des agents et le fonctionnement des identités d’agents dans Entra ID
- Point de contrôle n° 3 : Enregistrement d’un agent — avec et sans identifiant d’agent
- Point de contrôle n° 4 : Vérification des jetons et des revendications dans trois flux d'authentification Entra ID
- Chapitre 6 : Les risques liés aux identités d’agents dans Entra ID — et comment éviter la catastrophe
Note de bas de page
1 Ce blog est consacré aux environnements Microsoft Entra ID ; nous avons donc choisi de nous appuyer principalement sur des données provenant de sources Microsoft. Toutefois, des tendances similaires sont observées dans l’ensemble du secteur. Par exemple, le rapport « Entro NHI & Secrets Risk Report » a révélé que les identités non humaines sont 144 fois plus nombreuses que les identités humaines (!) en moyenne dans les environnements d’entreprise analysés, ce qui illustre clairement l’accélération du rythme d’intégration des identités basées sur du code dans les systèmes modernes.
