Nota del editor: Bienvenido al capítulo 1 de «Comprender y prevenir los ataques a la identidad de los agentes de Entra ID: una guía completa». Esta guía técnica, dividida en varias partes, te ayudará a comprender el enfoque de Microsoft respecto a las identidades de los agentes y cómo puedes protegerlas frente a los autores de amenazas. Para consultar todos los capítulos y las lecciones prácticas, empieza aquí.
Cualquier operación digital que traspase los límites de un sistema deja de ser simplemente «código». En el momento en que necesita interactuar con otro sistema de forma significativa —llamar a una API, leer datos protegidos o modificar un estado—, debe adoptar una forma estructural que otros sistemas puedan reconocer, evaluar y en la que puedan confiar. Esa forma es una identidad digital.
En la práctica, esto significa un objeto identificable respaldado por un directorio: una entidad de seguridad a la que se le pueden conceder permisos, asignar roles, ser evaluada por mecanismos de control de acceso y quedar registrada en los registros de auditoría. El código puede cruzar los límites libremente, pero, en teoría, no debería poder acceder a nada de valor sin hacerlo a través de una identidad.
Por este motivo, en las arquitecturas distribuidas, la identidad no es solo una representación o una capa de abstracción, sino la unidad de control. Los sistemas la intercambian y basan en ella las decisiones de acceso cuando es necesario: ya que traspasa fronteras, persiste más allá del entorno de ejecución que la creó y permite que las operaciones digitales existan y se ejecuten fuera de su contexto electrónico original.
A grandes rasgos, las identidades digitales en Microsoft Entra ID (y en la mayoría de los ecosistemas digitales modernos) se dividen en dos categorías: identidades humanas e identidades de máquina —o no humanas—. ¿Cuál es la diferencia?
Las identidades humanas representan a las personas. Los empleados, los trabajadores de primera línea, los clientes, los consultores, los proveedores y los socios suelen autenticarse como objetos de usuario. Inician sesión de forma interactiva, se someten a políticas de acceso condicional centradas en el usuario y, por lo general, operan bajo una única identidad principal.
Las identidades no humanas (NHI) representan, en definitiva, todo lo demás que opera dentro del sistema y que no es una persona. Estas identidades pueden dividirse, a grandes rasgos, en dos categorías principales:
- Identidades de dispositivos, que representan el hardware: dispositivos físicos como ordenadores de sobremesa, dispositivos móviles, sensores de IoT/OT y terminales gestionados
- Identidades de «carga de trabajo», que representan cargas de trabajo de software: aplicaciones, flujos de trabajo, scripts, cuentas de servicio, bots, agentes y otros tipos de cuentas de automatización
Independientemente de su tipo, la mayoría de las identidades siguen el mismo ciclo silencioso en el entorno digital. Se autentifican (demuestran al sistema al que se dirigen quiénes dicen ser); se autorizan ( el sistema determina qué pueden hacer en su contexto programable); y se registran ( sus acciones quedan registradas y son rastreables).
Este es el modelo clásico de autenticación, autorización y contabilidad (AAA). Se aplica a todo, tanto a personas como a entidades no humanas. Cada identidad accede a un sistema, solicita acceso, realiza una tarea y deja un rastro.
Es posible que este patrón te resulte familiar, ya que, poco antes de diseñar sistemas digitales, estructurábamos el mundo físico en torno a la identidad, la autoridad, la responsabilidad y, lo más importante, la confianza. Como desarrolladores, simplemente —y quizá de forma inconsciente— emulamos esos mismos arquetipos en el software.
Quizás por esa razón, la identidad digital se ha convertido en el plano de control de los recursos que la rodean. En consecuencia, la identidad es también la principal superficie de ataque para la manipulación, la suplantación de identidad y el uso indebido.
Por eso, cuando se ve comprometida una identidad digital, el atacante no altera ni modifica nada en el sistema. En cambio, actúa dentro de él bajo una identidad válida, moviéndose a través de los límites definidos por el software con afirmaciones y tokens legítimos. Las identidades no humanas no son una excepción a esta dinámica y, en la mayoría de los entornos, representan una exposición más amplia y mucho menos visible que la de los usuarios humanos.
En esta guía, analizamos un nuevo tipo de identidad no humana que Microsoft ha introducido recientemente en Entra ID: las identidades de agente.
Diseñado para dar respuesta al crecimiento rápido y, en cierta medida, imparable de los agentes de IA y de la categoría más amplia de cargas de trabajo de automatización, este modelo amplía las arquitecturas tradicionales de entidad de servicio, aplicación y usuario a un nuevo ámbito operativo.
Para comprender por qué esto es importante, primero debemos dar un paso atrás y entender que la mayoría de las identidades que operan en los entornos modernos en la nube no son personas en absoluto.
Por qué las identidades no humanas son, en realidad, más importantes que los usuarios
En el ámbito de la seguridad existe una vieja creencia, ya de origen digital, según la cual las cuentas de usuario son el tesoro más preciado que hay que proteger por encima de todo. Ese instinto tenía sentido cuando los seres humanos eran los principales actores en los sistemas digitales. Pero, una vez que la identidad se convierte en el plano de control y se multiplican las integraciones de software en todo el ecosistema de Internet, la escala pasa a ser el factor que define el riesgo.
En el Informe sobre el estado de la seguridad multicloud de Microsoft de 2024, esa magnitud se hace muy patente. El informe afirma:
«A medida que cada vez más empresas trasladan sus cargas de trabajo a la nube, estamos asistiendo a un rápido crecimiento del número de identidades de cargas de trabajo que se crean. En la actualidad, hay una identidad humana por cada diez identidades de cargas de trabajo. Este problema es aún más grave entre las pequeñas y medianas empresas, que tienen una identidad humana por cada 50 identidades de cargas de trabajo».
En los entornos de los clientes analizados en 2023, Entra Permissions Management identificó 209 millones de identidades en la nube. Más del 83 % de ellas no eran de personas.
Y eso fue en 2023.
Desde entonces, con la aceleración de las arquitecturas nativas de la nube, las integraciones a gran escala y la rápida adopción de automatizaciones basadas en la inteligencia artificial, el número de identidades no humanas ha aumentado de forma espectacular.1
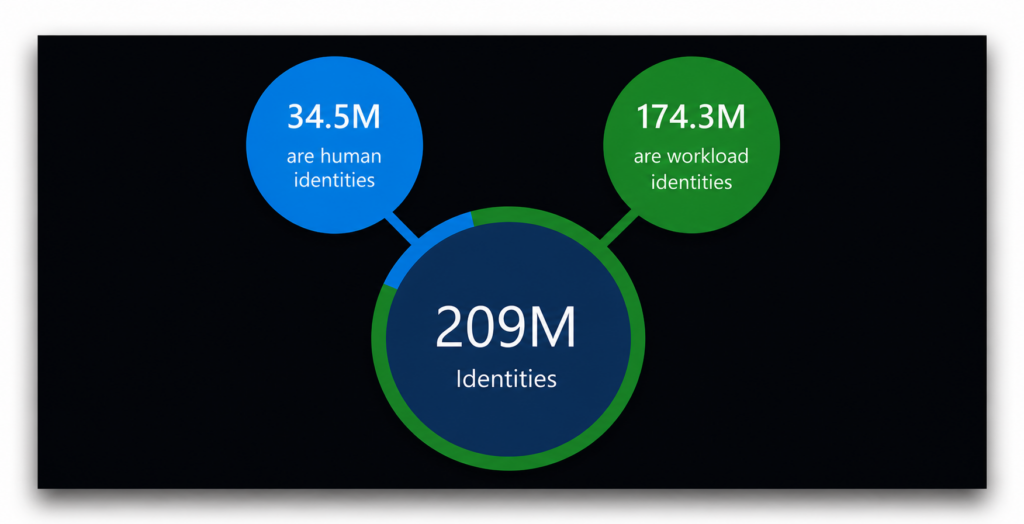
El volumen por sí solo ya justificaría que se le prestara atención. Pero la distribución de los privilegios hace que el panorama resulte aún más evidente.
En el mismo informe, Microsoft señaló que más del 50 % de esos 209 millones de identidades se clasificaban como «superidentidades», definidas simplemente como «una identidad de usuario o de carga de trabajo con acceso a todos los permisos y a todos los recursos de todo su entorno en la nube». Se trata, sin duda, de la «superidentidad» por excelencia.
El informe muestra además que los privilegios no se concentran en los usuarios. La mayoría de las identidades con mayor poder en el entorno no son personas, sino código.

La siguiente pregunta es: ¿qué riesgos plantean las diferentes identidades no humanas?
Por lo tanto, las identidades no humanas no solo predominan en número, sino también en alcance. Las identidades no humanas pueden funcionar de forma continua, autenticarse mediante programación y, a menudo, disponen de rutas de acceso persistentes a través de los servicios y la infraestructura. Además, no cuestionan las instrucciones inusuales y, a diferencia de los usuarios, nadie inicia sesión cada mañana para comprobar si se comportan como se espera.
Ese es el contexto en el que operan los entornos modernos en la nube.
Sin embargo, antes de poder analizar los riesgos que plantean estas identidades, primero debemos comprender en qué consisten realmente.
El término «identidad de carga de trabajo» se utiliza con frecuencia en la documentación de Microsoft y en los debates sobre seguridad; sin embargo, en la práctica hace referencia a un conjunto de diferentes tipos de identidad que Entra ID pone a disposición de forma interna.
Cada uno de estos tipos tiene una finalidad operativa distinta, sigue un ciclo de vida diferente y conlleva sus propias implicaciones en materia de seguridad. Para comprender qué papel desempeñan las identidades de agente en este contexto, primero debemos desentrañar la taxonomía de las identidades de cargas de trabajo en Entra ID.
Para conocer los detalles, sigue leyendo en el siguiente artículo: «La taxonomía de las identidades de carga de trabajo en Entra ID: aplicaciones empresariales, entidades de servicio y otras formas de confusión organizada».
Explora la guía
Pasa al siguiente capítulo publicado de la serie… o elige tu propia aventura.
- Introducción: Cómo comprender y prevenir los ataques a la identidad de los agentes de Entra ID: una guía completa
- Capítulo 1: Conoce las identidades de los agentes de Entra ID (por cierto, no son personas)
- Capítulo 2: La taxonomía de las identidades de carga de trabajo en Entra ID: aplicaciones empresariales, entidades de servicio y otras formas de confusión organizada
- Capítulo 3: Introducción al ID de Microsoft Agent y a la plataforma de identidad de Agent
- Punto de control práctico 1: Creación de un identificador de agente con MS Graph
- Capítulo 4: Identidades de los agentes: análisis en profundidad del diseño
- Punto de control práctico 2: Configuración de los permisos de identidad de los agentes
- Capítulo 5: El registro de agentes y cómo funcionan las identidades de los agentes en Entra ID
- Punto de control práctico n.º 3: Registro de un agente: con y sin ID de agente
- Punto de control práctico 4: Verificación de tokens y reclamaciones en tres flujos de autenticación de Entra ID
- Capítulo 6: Dónde pueden surgir problemas con las identidades de los agentes en Entra ID, y cómo evitar el desastre
Nota final
1 Este blog se centra en los entornos de Microsoft Entra ID, por lo que hemos decidido basarnos principalmente en datos procedentes de fuentes de Microsoft. Sin embargo, se observan patrones similares en el resto del sector. Por ejemplo, el informe «Entro NHI & Secrets Risk Report» reveló que las identidades no humanas superan en número a las identidades humanas en una proporción media de 144:1 (!) en los entornos empresariales analizados, lo que demuestra claramente la aceleración a la que se están integrando las identidades basadas en código en los sistemas modernos.
